TL;DR: An SLA clause is the operational backbone of any vendor relationship. It defines performance standards (uptime, response time, resolution time), how those standards are measured, and what happens when they are missed. Service credits are the standard remedy, but they rarely compensate for actual business losses. The real leverage is termination rights for chronic underperformance. In 2025-26, SLA drafting must also address AI service reliability, multi-cloud failover, and cybersecurity incident response. If your SLA does not include automatic credit application, objective third-party measurement, and escalating termination triggers, you are leaving your vendor with no financial incentive to meet its commitments.
Service Level Agreements sit at the heart of vendor risk management. An SLA answers a simple but critical question: what level of performance am I paying for, and what do I get if I don't receive it? For cloud platforms, SaaS vendors, and managed service providers, SLAs are the operational contract - the part that matters every single day.
2025-26 introduced new SLA complexities. Cloud infrastructure outages have become routine - AWS, Azure, and Google Cloud each experienced multi-hour regional failures that cascaded into customer downtime. AI services added a new wrinkle: how do you SLA reliability for a service that occasionally hallucinates? Cybersecurity incidents (MOVEit, SolarWinds, and their successors) exposed gaps in vendor security SLAs. Remote work dependency means that SaaS uptime now directly impacts employee productivity - a Teams or Slack outage hits every organization simultaneously. Government cloud mandates (FedRAMP for federal agencies) introduced compliance-based SLAs. And multi-cloud strategies, which many organizations adopted to avoid vendor lock-in, created complexity: if your workload spans AWS, Azure, and Google Cloud, whose SLA applies when one region fails but others don't?
A well-structured SLA defines: the specific metrics (uptime percentage, response time, resolution time), how they're measured, what happens if they're missed (service credits are the usual remedy, not actual damages), when the SLA doesn't apply (scheduled maintenance, force majeure), and what triggers escalation or termination rights. The SLA must be realistic - promising 99.99% uptime when historical data shows 99.5% is achievable invites constant disputes.
Core SLA components:
• Service level metrics - uptime percentage (99.5%, 99.9%, 99.99%), response time (4 hours, 1 hour), resolution time (8 hours, 24 hours)
• Measurement and reporting - how uptime is calculated (agent-based monitoring, synthetic probes, customer-reported incidents), who reports it, when
• Service credits - automatic refunds or account credits if service misses SLA, typically escalating (10% credit for 99-99.5% uptime, 25% for 95-99%)
• Exclusions - scheduled maintenance windows, force majeure, customer misuse, third-party integrations
• Escalation procedures - when to engage senior support, expected response times for critical vs non-critical issues
• Termination for chronic failure - if service credits get triggered repeatedly, buyer can terminate without penalty
Typical Service Levels and Metrics
- Uptime percentage is the most common metric. It's the percentage of time the service was available divided by total time in the month. 99.5% uptime means 21 minutes of acceptable downtime per month. 99.9% means 4.3 minutes. 99.99% means 26 seconds. Each nine adds cost and operational burden. Choose what you actually need, not what sounds good.
- Response time
- Resolution time is when the issue is actually fixed. "Non-critical issue: 8-hour resolution SLA" is ambitious. More realistic is "use commercially reasonable efforts to resolve within 8 hours," which gives the vendor some protection if the fix takes longer.
- AI service SLAs introduced a dilemma in 2025-26. How do you SLA a language model's accuracy? Vendors typically avoid "output quality" SLAs and instead focus on "service availability" (the API is up) and "response time" (queries are processed), not whether the AI's answers are correct. This is a negotiation point: buyers want accuracy guarantees; vendors resist them because LLM outputs are probabilistic.
- Multi-cloud SLAs require careful drafting. If you run workloads across AWS, Azure, and Google Cloud, your overall availability depends on all three. An SLA with each vendor individually doesn't guarantee your overall uptime - you need to layer them carefully.
Service Credits vs. Actual Damages
- Service credits are the remedy for SLA misses - automatic account credits or refunds, usually a percentage of the monthly fee. If the vendor misses 99.9% uptime, you get 10% of that month's fee back. They're predictable, automatic, and don't require proving actual damages.
- Actual damages are what you actually lost - lost revenue, business interruption, employee downtime. These are hard to prove, heavily disputed, and vendors resist them fiercely. That's why most SLAs cap total liability at the service fees for that month or quarter. Once service credits hit, that's the exclusive remedy.
- Service credits are rarely material. A 10% credit for missing 99.9% uptime sounds good until you realize that's $100 credit on a $1,000/month service. You've lost far more than that in business disruption. That's the tension: vendors limit their exposure via service credits, while buyers want meaningful financial pain if service fails.
- Escalating credits are more buyer-friendly: 10% credit if downtime is 10+ minutes, 25% if 100+ minutes, 50% if 500+ minutes, plus termination right if this happens 3x in 6 months. This makes vendors care more about uptime because repeated failures become expensive.
A well-drafted SLA Clause contains:
- Clear service scope: Which services are covered by the SLA? The core SaaS application, yes. Third-party integrations you've approved, maybe not. Customer-provided data that's corrupted, definitely not. Be specific about what is and isn't included.
- Defined metrics: "99.5% monthly uptime" is clear. "Best efforts" is not an SLA - it's a disclaimer of SLA. Specify the metric, the measurement period (monthly), and the calculation methodology (e.g., "uptime is measured by synthetic monitoring pings from geographically diverse data centers every 60 seconds").
- Measurement and verification: Who measures uptime - the vendor's own monitoring, a third-party monitor, or customer reports? Vendor self-measurement is inherently suspect. Third-party monitors (Pingdom, etc.) are more objective. Customer-reported incidents invite disputes.
- Service credit schedule: A clear table showing: if uptime falls below 99.5%, credit is 10%; below 99%, credit is 25%; below 95%, credit is 50%. Make the increments meaningful so the vendor feels the pain.
- Exclusions and force majeure: Scheduled maintenance windows (maybe 4 hours per month), security incidents (patching a zero-day), customer misuse, third-party service failures (if your vendor depends on AWS and AWS has an outage, does that trigger your vendor's SLA miss?). Define these clearly or disputes will be endless.
- Claim and credit procedures: How does the buyer claim service credits? Automatically deducted from the next invoice? Customer must submit a claim? If the vendor doesn't publish monthly uptime reports within 5 days, is uptime deemed compliant? Include teeth here - if the vendor doesn't report, buyer wins by default.
- Escalation and termination: If service credits are triggered 2 months in a row, does the buyer have the right to escalate to the vendor's COO? If service credits are triggered 3 months in 6, can the buyer terminate without penalty? Termination rights are the real hammer.
Market Position & Benchmarks
Where Does Your Clause Fall?
- Vendor-Favorable: 99% uptime commitment, vendor self-measured, service credits capped at 10% of monthly fees, credits require written claim within 15 days, broad exclusions (scheduled maintenance, third-party outages, customer-side issues), no termination right for SLA misses, "commercially reasonable efforts" resolution language.
- Market Standard: 99.5% uptime commitment, third-party or vendor-published monitoring with customer audit rights, service credits escalating from 10-25% of monthly fees, automatic credit application, moderate exclusions (scheduled maintenance with 48-hour notice, genuine force majeure), termination right after 3 SLA misses in a rolling 6-month period, defined response and resolution times by severity.
- Buyer-Favorable: 99.9%+ uptime commitment, independent third-party monitoring, service credits escalating from 10-50% of monthly fees, automatic credit with no claim requirement, narrow exclusions (only scheduled maintenance with 72-hour notice and customer-caused incidents), termination right after 2 SLA misses in any rolling 6-month period, right to actual damages for catastrophic failures exceeding 24 hours, vendor-funded disaster recovery testing.
Market Data
- Major cloud IaaS providers (AWS, Azure, Google Cloud) commit to 99.99% uptime per region, but actual delivered uptime across all regions averaged 99.95-99.97% in 2025, with at least one multi-hour regional outage per provider per year.
- Enterprise SaaS vendors typically commit to 99.5% uptime in standard agreements, with 99.9% available as a premium SLA tier at 15-30% price uplift.
- Service credit caps in enterprise SaaS agreements average 15-25% of monthly fees for the affected period. Only approximately 10-15% of enterprise contracts include credits exceeding 30% of monthly fees.
- Automatic credit application (no claim required) appears in roughly 35-40% of enterprise SaaS agreements, up from approximately 20% in 2022, reflecting buyer negotiation pressure.
- Termination rights for chronic SLA failure appear in approximately 55-60% of enterprise agreements, typically triggered after 2-3 SLA misses in a 6-12 month rolling period.
- AI-specific SLAs (covering model availability, API response time, and throughput) appear in fewer than 20% of AI vendor agreements as of early 2026; most vendors avoid output-quality commitments entirely.
Sample Language by Position
Vendor-Favorable: "Service Provider will use commercially reasonable efforts to maintain 99% monthly uptime for the Service. If monthly uptime falls below 99%, Customer may request a service credit equal to 10% of the monthly fees for the affected Service, provided Customer submits a written claim within fifteen (15) days of month-end. Service credits are Customer's sole and exclusive remedy for uptime failures. Uptime excludes scheduled maintenance (up to 8 hours per month), force majeure, Customer-caused incidents, and third-party service disruptions."
Market Standard: "Service Provider warrants 99.5% monthly uptime, measured by Service Provider's monitoring system with reports published to Customer within 5 business days of month-end. If uptime falls below 99.5%, Customer receives service credits automatically applied to the next invoice: 99-99.4% = 10% credit; 95-99% = 25% credit. Downtime excludes scheduled maintenance (maximum 4 hours per month, 48-hour advance notice) and Customer-caused incidents. If SLA is missed in 3 or more months within any rolling 6-month period, Customer may terminate for convenience upon 30 days' written notice."
Buyer-Favorable: "Service Provider guarantees 99.9% monthly uptime, measured by independent third-party monitoring (mutually agreed provider). If monthly uptime falls below 99.9%, service credits are automatically applied: 99.5-99.8% = 10% credit; 99-99.4% = 25% credit; 95-99% = 50% credit; below 95% = 100% credit for that month. Customer need not submit a claim. Exclusions are limited to: (a) scheduled maintenance not exceeding 2 hours per month with 72-hour notice, and (b) incidents caused by Customer's material breach of the acceptable use policy. If SLA is missed in 2 or more months within any rolling 6-month period, Customer may terminate without penalty and receive a pro-rata refund of prepaid fees. For outages exceeding 24 continuous hours, Customer retains the right to pursue actual damages notwithstanding the service credit structure."
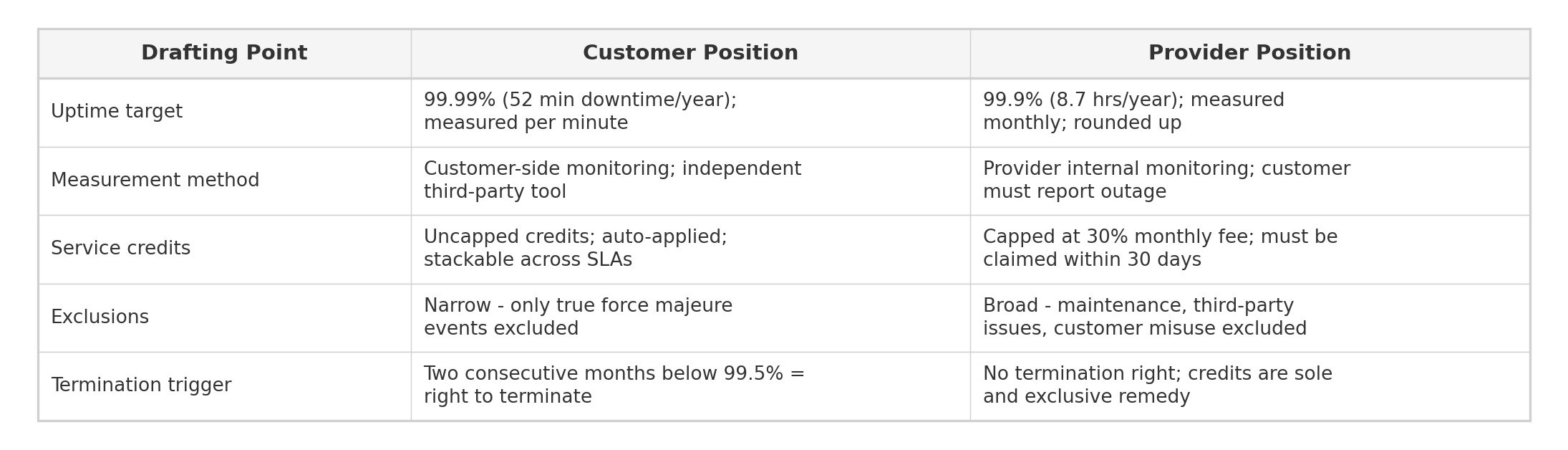
Buyer vs Vendor:
SLA language varies widely depending on the service type and buyer leverage. Here are two approaches:
- Vendor-favorable: "Vendor will use commercially reasonable efforts to maintain 99% uptime (measured monthly, excluding Scheduled Maintenance). Service credits are Buyer's exclusive remedy for uptime misses. Vendor is not liable for any downtime caused by customer misuse, third-party services, or events beyond Vendor's reasonable control."
- Buyer-favorable: "Vendor warrants 99.5% monthly uptime, measured by Vendor's monitoring published daily. If uptime falls below SLA, Buyer receives service credits: 10% for 99-99.4%, 25% for 95-99%, 50% for <95%, plus termination right if SLA is missed 2+ months in any rolling 6-month period. Credits are automatically deducted from the next invoice."
Sample Clause Language:
Example 1: Enterprise SaaS SLA with Escalation
"Service Provider warrants that the Service will maintain monthly uptime of not less than 99.5% (calculated as (total minutes in month - downtime minutes) / total minutes in month). Uptime is measured via continuous automated monitoring from geographically distributed monitoring agents, with 60-second polling intervals. Service Provider will publish uptime reports to Customer within 3 business days of month-end. Downtime excludes: (i) Scheduled Maintenance windows (max 4 hours per month, performed during off-peak hours with 48-hour advance notice), (ii) customer-caused downtime (misconfigurations, API abuse, DDoS), (iii) third-party service failures (AWS outages, ISP failures), and (iv) force majeure events. If monthly uptime falls below SLA, Customer receives service credits: 99-99.5% = 10% monthly fee; 95-99% = 25% monthly fee; <95% = 50% monthly fee. Credits are automatically applied to the next invoice and are Customer's exclusive remedy for uptime misses. If SLA is missed in any 2 months within a 6-month rolling period, Customer may engage Service Provider's VP of Customer Success to discuss remediation plan. If SLA is missed in 3 months within any 6-month rolling period, Customer may terminate this Agreement for convenience without penalty."
Example 2: Cloud Infrastructure SLA (IaaS with Regional Redundancy)
"Service Provider guarantees 99.99% uptime for each service region (US-East, US-West, EU-Central, Asia-Pacific), measured independently per region. Uptime calculation: (minutes in month - region downtime minutes) / minutes in month. A region is considered down only if Service Provider's own monitoring confirms unavailability for 5+ continuous minutes across all availability zones in that region. Customer's use of multiple regions does not entitle Customer to cumulative uptime guarantees. If a single region misses 99.99% uptime, Customer receives service credits applied to that region's charges: 1 hour downtime = 10% credit, 4+ hours = 25% credit, 8+ hours = 50% credit, 24+ hours = 100% credit. Scheduled maintenance windows (max 1 per month, 30 minutes) and emergency security patches are excluded. Customer must submit credits claims within 30 days of month-end with supporting evidence. If Customer submits no claim, credits are forfeited."
Contract types where SLA Clause is critical:
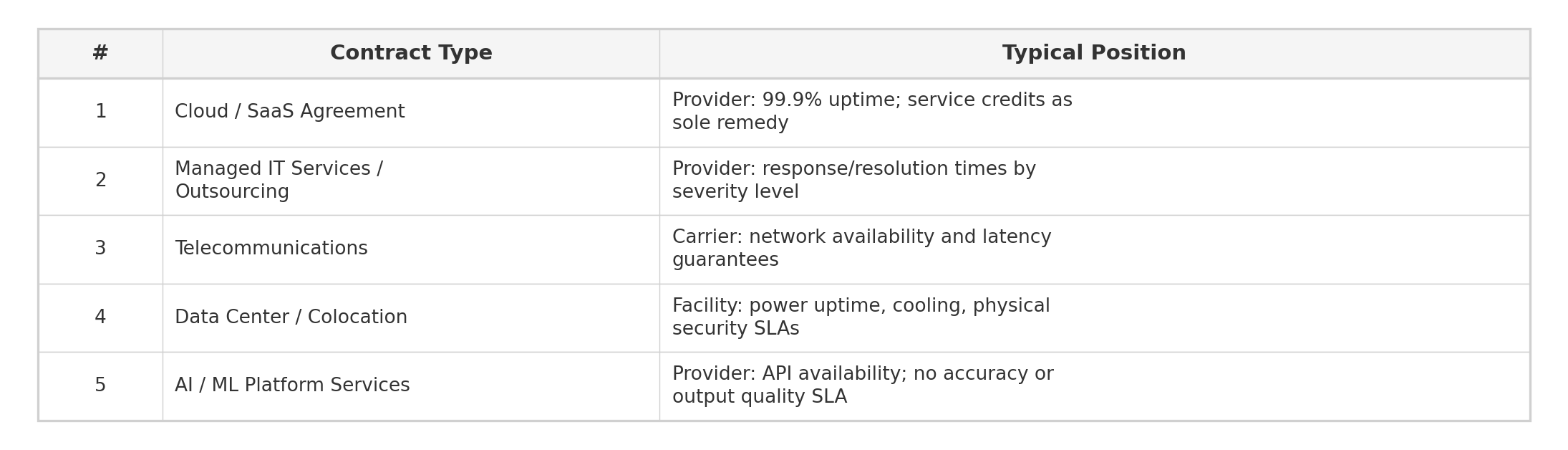
Common structures and market practices:
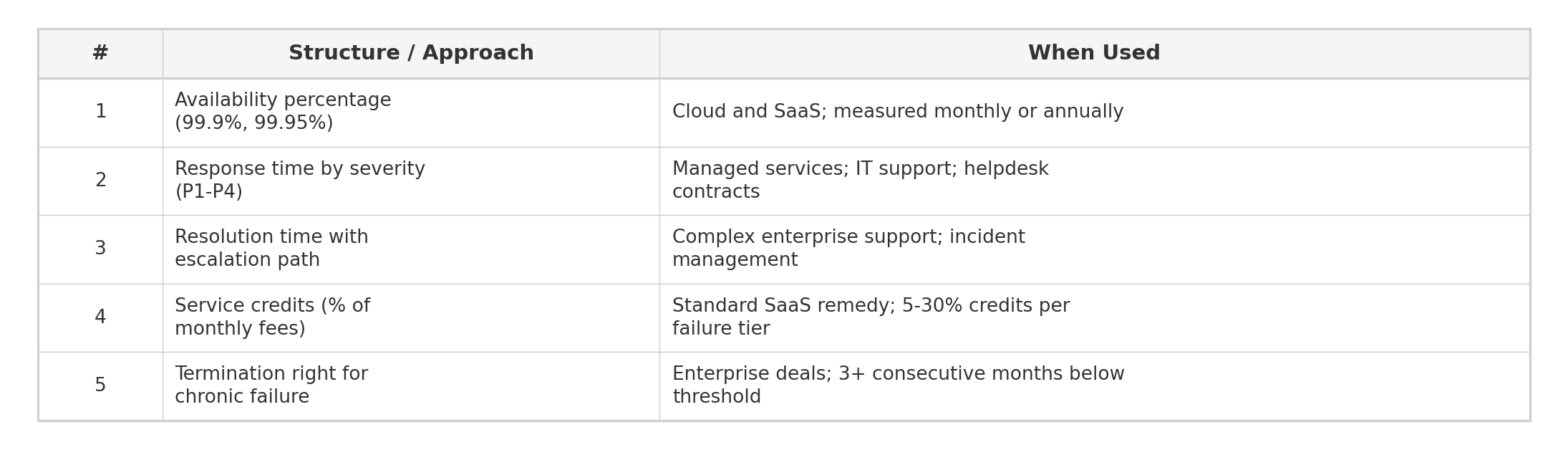
Negotiation Playbook
Key Drafting Notes
- Require vendor-published uptime reports with audit rights. A vendor that self-reports uptime without customer verification has every incentive to exclude borderline incidents. Require monthly reports published within 5 business days of month-end, with the right for the buyer to audit measurement methodology annually. If the vendor fails to publish on time, uptime should be deemed to have missed the SLA for that period.
- Separate SLA tiers by service criticality. Not every service component warrants the same uptime commitment. The core application may require 99.9%; reporting dashboards and analytics may warrant 99.5%; batch processing and data exports may be best-efforts. Tiered SLAs prevent disputes about non-critical outages triggering credits and allow the vendor to price the commitments appropriately.
- Address the "what about your vendor's vendor" problem explicitly. If your SaaS provider runs on AWS and AWS has a regional outage, does that excuse your provider from its SLA? Vendor-favorable language excludes third-party outages entirely. Buyer-favorable language holds the vendor accountable regardless of root cause, because the buyer has no contract with AWS. The market compromise: exclude third-party outages only if the vendor notifies the buyer within 2 hours and provides a root-cause analysis within 5 business days.
- Build in escalation before termination. Immediate termination for a single SLA miss is impractical for both parties. A well-structured escalation ladder (first miss triggers a remediation plan, second miss triggers executive engagement, third miss triggers termination right) gives the vendor a chance to fix systemic issues while preserving the buyer's exit option if problems persist.
- Negotiate for actual-damages rights on catastrophic failures. Service credits are adequate for routine SLA misses (a few minutes of downtime). They are not adequate for a 48-hour outage that shuts down the buyer's operations. Negotiate a carve-out: for outages exceeding a defined threshold (e.g., 24 continuous hours or total monthly downtime exceeding 4 hours), the buyer retains the right to pursue actual damages outside the service credit framework. Most vendors will resist this, but it is increasingly accepted in enterprise deals.
Common Pitfalls
- Accepting "commercially reasonable efforts" as an SLA. This is not an SLA; it is a disclaimer of SLA. "Commercially reasonable efforts to maintain 99.5% uptime" means the vendor tried but does not owe you anything if it fails. A real SLA commits to a specific metric and attaches a financial consequence for missing it. If the vendor insists on "efforts" language, counter with: "Vendor commits to 99.5% uptime. If uptime falls below this target, service credits apply as follows."
- Allowing vendor self-measurement without audit rights. Vendors control their own monitoring tools, alert thresholds, and incident categorization. Without audit rights or independent verification, the vendor decides whether an outage "counts." Require either third-party monitoring or the right to audit the vendor's measurement methodology annually.
- Overlooking the credit-claim mechanism. Many SLA agreements require the buyer to submit a written credit claim within 15-30 days. In practice, IT teams are busy resolving the outage's business impact and miss the claim window. Negotiate automatic credit application with no claim requirement, or at minimum extend the claim window to 60-90 days.
- Failing to define "downtime" precisely. Is the service "down" if it responds but with 30-second latency? If 50% of users can access it but 50% cannot? If the API returns errors but the web UI works? Define downtime in measurable terms: "Downtime means any period during which the Service is unavailable or response time exceeds [X] seconds for [Y]% or more of requests, as measured by [monitoring methodology]."
- Ignoring the interaction between SLA credits and liability caps. Service credits are typically carved out from the general liability cap (they are not "damages" but a price adjustment). Verify this explicitly. If service credits count toward the liability cap, a single bad month could exhaust the entire cap, leaving the buyer with no additional remedy for other contract breaches.
Key drafting notes for an SLA Clause:
- Make sure the SLA is realistic: Requiring 99.99% uptime when the vendor's actual historical performance is 99.5% invites constant disputes and gaming (the vendor will find exclusions to avoid paying credits). Use historical data to set achievable targets.
- Define measurement methodology clearly: Vendor self-monitoring vs. third-party monitoring vs. customer-reported incidents all give different results. Decide upfront who measures and how. Synthetic probes from geographically diverse locations are more objective than vendor internal logs.
- Make service credits automatic and substantial: If the vendor has to cut you a check or wait for you to ask for credits, half of them never happen. Automatic deduction from the next invoice is cleaner. And make the credit percentage hurt - 5% is nothing, 25-50% gets attention.
- Address multi-service dependencies: If your SLA depends on your vendor's vendor (e.g., vendor relies on AWS), clarify whether your vendor's SLA miss caused by AWS's outage triggers your vendor's SLA miss or is excluded. This is a real battlefield in 2025-26 with cloud outages happening regularly.
- Termination rights are the real remedy: Service credits rarely equal actual business loss. The threat of termination for chronic SLA failure is what makes vendors care. Include escalating termination rights: after 2 misses in 6 months, buyer can terminate for convenience.
Historic note:
Service Level Agreements emerged in the late 1990s as businesses moved to outsourced hosting and ASP (Application Service Provider) models. Early SLAs were basic - "99.5% uptime." Over time, SLA sophistication increased: multi-tiered credits, escalation procedures, termination rights. The shift to cloud computing (AWS, 2006 onwards) introduced regional SLAs and availability zones. The 2013 AWS outage taught the industry that even "enterprise-grade" providers fail. By 2020, SLAs had matured into complex instruments with exclude clauses, measurement methodologies, and credit calculations. The 2020-2025 period saw a surge in SLA litigation as COVID-era remote work made SaaS uptime mission-critical and outages had immediate business impact. The shift to AI services in 2023-2025 exposed SLA blindspots: traditional uptime SLAs don't address output quality or hallucination rates, leaving buyers unprotected.
Jurisdiction specific notes:
- U.S.: SLAs are contractual commitments, not regulatory mandates, so parties can define SLA terms freely. However, UCC Article 2 (sale of goods) and common law implied warranty of merchantability may impose baseline service quality expectations. Service credits are treated as liquidated damages (not a penalty) if they approximate actual damages. Courts will enforce reasonable SLAs but may strike down unreasonable caps on liability as unenforceable limitations of liability.
- U.K.: Under the Consumer Rights Act 2015, services must be performed with reasonable care and skill. Business-to-business SLAs are enforceable as written. The concept of "reasonable care" can override written SLA terms if courts find the SLA is unreasonably one-sided, but this is hard to prove. Service credits are enforceable liquidated damages clauses if they bear a reasonable relationship to anticipated harm.
Drafting tip:
In regulated industries (banking, healthcare, government), SLAs may need to comply with regulatory minimums. FedRAMP-required services must meet federal uptime and security standards. HIPAA-covered entities need SLAs from their Business Associates that guarantee uptime and security. Build regulatory requirements into your SLA negotiation from the start.
Bottomline:
An SLA is only as good as the remedy it provides. If service credits are small and optional (require the buyer to ask for them), vendors will game the system and customers will accept chronic under-performance. A strong SLA is clear on metrics (specific percentages), measurement (objective third-party methodology), remedies (automatic substantial credits), and escalation (termination rights for repeated failure). In 2025-26, add SLA language around AI output reliability, cybersecurity incident response, and multi-cloud failover expectations. And remember: the most important SLA provision is the termination right. If the service keeps failing, you need the legal right to walk away without penalty.
.avif)



